


你的位置:炒股杠杆操作_炒股杠杆官网_实盘股票杠杆开户 > 炒股杠杆操作 > 辽阳股票配资 深度理解:OpenAI最新发布的“强化微调”
发布日期:2024-12-16 22:53 点击次数:65

为证券之星据公开信息整理辽阳股票配资,由智能算法生成,不构成投资建议。
为证券之星据公开信息整理,由智能算法生成,不构成投资建议。
今天主要分享一下OpenAl发布会第二天发布的核心内容"强化微调”,为什么奥特曼会觉得这是一项惊喜技术,为了深入了理解它,我周末花了一天的时间深入的去研究它,本文分享一下我的研究结果!

个人对OpenAI发布“强化微调”的感受:
OpenAI发布会第二天发布的内容依然没有推出全新的模型,仍旧是在原有的技术体系下推出升级的内容,说实话网上骂声一片都是痛批“这是什么玩意的?”,基本都是营销人而不是开发者,他们要的是营销噱头,根本不管推出的东西有没有用,而作为AI应用开发者而言,反而觉得能推出一些立刻应用于应用研发的能力更加实在,像Sora这种噱头性的东西,于我们这些创业者而言完全没有意义,所以个人反而觉得,OpenAI第二天推出“强化微调”这个能力,虽然没有太多的惊喜,但是更加实在;
一、强化微调是什么,和传统SFT有什么区别?

1. 从实现方法上看
SFT是通过提供人工标注数据(例如正确的输入-输出对),告诉模型什么才是正确的答案,然后让模型学会模仿这些答案,做出正确的回答;
而RFT是把传统的SFT+奖励模型+强化学习这三个环节整合在一起,在一套闭环的流程里面完成三者的运行,并且该流程是自动运行的,它的作用,就是可以自动的优化基础模型,让模型越来越聪明,回答的效果越来越好;
RFT能够让模型和回答结果越来越好的原理是“它让SFT+奖励模型+强化学习这个优化模型和生成结果的机制能够不停的运转”;
首先我们提供一部分“正确答案”的数据让模型完成SFT从而能回答正确的答案;之后,该流程会根据人工提供的、或者系统实时收集的反馈数据(比如生成结果的评分数据)训练一个奖励模型(一个评分模型,用于对生成结果打分),并且这个模型会随着反馈数据的动态更新自动的优化评分函数和评分能力,并通过这个奖励模型,优化基础模型,让基础模型越来也好;并且这整个闭环是循环自动完成的,因为这套循环机制,从而让生成结果越来越好;
RFT看起来像是把之前的“SFT+奖励模型+强化学习”这三个合并一下然后重新包装一下,实际上还是有些不同,具体看下一部分的内容,简单讲:
RFT=自动化运行且动态更新的“SFT+奖励模型+强化学习”
2.本质差异
SFT不会动态的迭代和优化基础模型,只是让模型模仿一部分正确的答案然后做出回答;RFT则会动态的迭代和优化基础模型,并且会动态迭代正确答案以便持续的完成SFT的过程,同时还会动态的优化奖励模型,从而让奖励模型越来越好,进而用奖励模型优化基础模型;整个过程,基础模型慢慢的掌握回答正确答案的方法,越来越聪明,相比SFT只是模仿作答有明显的差异;
3.需要的数据量
需要大量的人工标注数据,并且SFT的效果,依赖数据规模;而RFT只需要少量的微调数据,然后利用RFT动态优化模型的机制,就可以让模型变强大;
二、强化微调和传统的”SFT+奖励模型+强化学习RLHF“有什么区别?
SFT+奖励模型+强化学习RLHF这一套机制已经不是什么新鲜玩意了,所以当看到RFT其实就是把三者合并在一起这个观点的时候会以为这仅仅是简单做了一个合并然后重新包装一个概念出来,事实上并不完全如此,如果仅仅是这样的话,根本无法实现推理效果变得更好,认真研究了一下其中的差异,具体如下,为了方便理解,我整理了两个逻辑图如下:
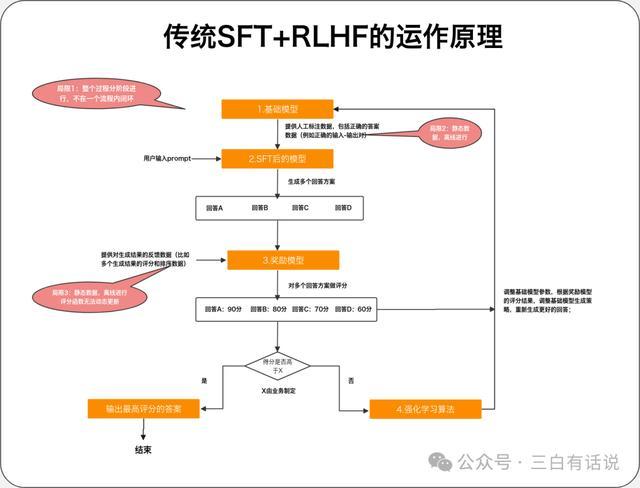
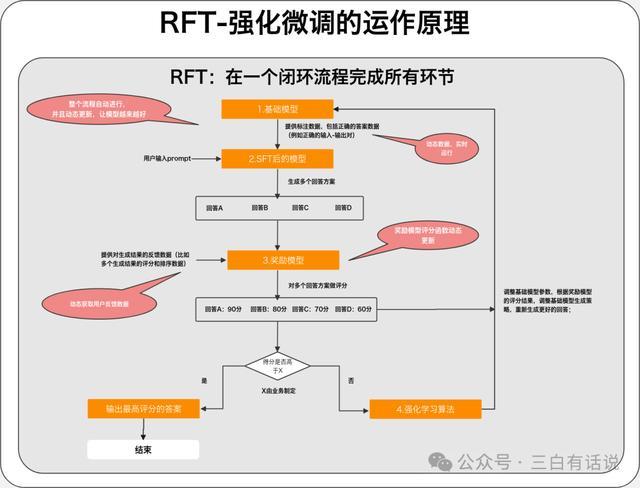
1. 传统的SFT+奖励模型+强化学习 的工作原理
1.SFT:通过提供人工标注数据(例如正确的输入-输出对),告诉基础模型什么才是正确的答案,然后让模型学会模仿这些答案,做出正确的回答;
2.奖励模型:通过提供对生成结果的反馈数据(比如多个生成结果的评分和排序数据),训练一个评分模型,用于对模型生成的多个结果进行评分,奖励模型本质上也是一个小一点的模型,它可以是基于大模型训练的模型,也可以是传统的神经网络模型;奖励模型的核心包括2部分内容:
①评分函数:包括多个对生成结果评分的维度,比如生成结果的准确性、简易性、专业度等等,然后构建一个评分函数;
②反馈数据:人工或者机器对生成结果做反馈和评分的数据,用于训练评分模型
3.强化学习:奖励模型对模型初始生成的多个结果做评分后,将这些评分结果提供给基础模型,然后基于强化学习算法,调整基础模型的参数,让模型根据评分结果调整生成的策略,这个过程中,模型可能会了解评分结果中哪些维度得分低,哪些维度得分高,从而尝试生成更好的结果;
2. SFT+奖励模型+强化学习 运行的过程
基础模型结合人工标注数据之后,微调一个模型出来,用于生成回答结果,这时模型生成的结果可能有ABCD多个;
奖励模型对多个生成结果进行评分,评估生成结果的得分,如果其中最高的得分已经达到了优秀结果的标准(标准可以是人工或者算法制定),则直接输出最高得分的结果;如果生成结果不行,则启动强化学习;
通过强化学习算法,模型基于评分结果进一步的调整模型,让模型尝试生成更好的结果,并循环整个过程,知道输出满意的结果;
3. SFT+奖励模型+强化学习存在的问题
SFT阶段:需要整理大量的人工标注数据,成本比较高,并且每次迭代都需要更新数据,整个过程是离线进行的;
奖励模型阶段:奖励模型的评分函数不能动态更新,每次更新都需要离线进行,并且反馈数据也是离线的,无法实时的更新反馈数据;
基础模型优化阶段:基础模型的优化也是离线的,无法自动优化基础模型;
4. RFT与SFT+奖励模型+强化学习的区别
SFT阶段:动态的获取评分比较高的结果用于做微调数据,持续的调整SFT的效果;
奖励模型阶段:奖励模型的评分函数自动优化和调整,反馈数据动态更新;
基础模型优化阶段:动态的获取奖励模型的评估结果,通过强化模型,动态的优化基础模型
以上的整个过程,都是自动完成,并且动态的更新;
三、奥特曼为什么要强调这个更新点,为何模型的迭代方向是重视微调环节
1. 微调技术有利于让开发者更好的利用现有的模型能力
当下的模型事实上还没有真正的被充分的利用,现在市场对于现有模型能力都还没有消化完,持续的推出新的能力对于应用的落地并没有太大的帮助,所以预期持续的推出很多信息量很大的新的东西,不如首先先把现有的模型能力利用好,而提供更好的模型训练和微调的能力,有利于帮助开发者更好的利用现有的模型开发出更好的应用;
2. 微调技术有利于帮助开发者更好的将大模型落地于应用场景
大模型的落地需要结合场景,将大模型应用到具体的应用场景的核心,就是微调技术
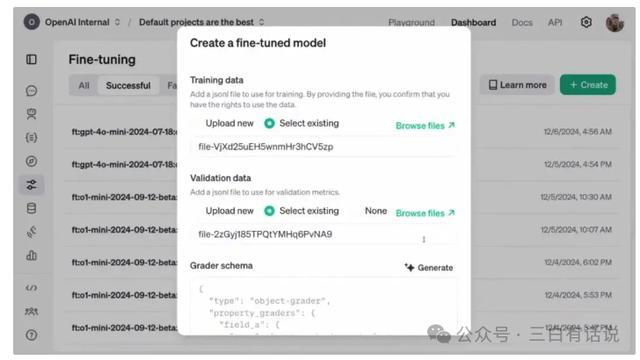
四、强化微调模型怎么使用?
目前通过OpenAI官网创建微调模型,并上传微调数据,就可以通过强化微调微调一个模型,操作还是相对比较简单的;目前可以基于O1和GPT4o做强化微调,两者在价格和能力上有明显差别;
五、强化微调会带来什么改变?
1. 开发者可以投入更少的成本,微调获得一个更强大的模型;
如前面提到了,开发者只需要上传少量的数据,就可以完成微调,这可以极大的降低开发者微调模型的成本,提高微调的效率,并且根据官方发表的观点,通过微调后的O1,运行效果甚至可以超过O1完整版和O1-mini,这让大模型的微调成本进一步的下降,普通创业者也能轻松的微调模型;
2. 开发者可以更好的将大模型应用于具体的场景;
大模型的场景化应用逻辑,依赖模型微调,微调门槛的下降,意味着开发者可以更加轻松的实现AI应用的落地并提升应用的效果;
六、强化微调对于企业的应用有哪些?
以我的创业产品AI快研侠(kuaiyanai.com)的业务为例,强化微调的好处,可能是能够让我们能够基于可以整理的数据,快速的微调一个用于研报生成的模型,从而提升研报的生成的效果;
不过目前海外的模型使用不了的情况下,只能依赖国内的模型也能尽快实现该能力,还是希望国内大模型厂商们能加油,尽快追赶上海外的技术,造福我等创业者;
七、我的一些思考
1)从当下模型的发展方向的角度上,大模型的迭代路径依然集中在如下几个方向:
解决数学计算、编程、科学方面的问题上,这三者代表了模型的智能程度,从OpenAI最新发布O1完整版能力,可以看到这点,
支持更强大的多模态能力:提升多模态大模型的能力,Day1发布会的时候,现场演示了拍摄一个手绘图,就能计算复杂的问题,除了体现计算能力,也在体现多模态的能力;
提升思考能力:增强以思维链为代表的,自我学习和自我思考的能力;
降低训练和微调的难度:让开发者可以更轻松的完成模型的训练和微调;
2)当下提升模型的能力的重点,除了模型架构的优化,其次可能术、微调技术
我们可以看到之前从GPT3.5到GPT4,其中模型能力的迭代关键可能在于模型的架构,现在模型的架构的边际优化提升可能比较低了,接下来可能重点在于训练技术,其中强化学习可能是提升模型能力的关键手段,因此国内的模型应该会重点聚焦在强化学习的能力提升上;还是在训练技
还是比较期待接下来10天辽阳股票配资,OpenAI发布会的内容,或许还有很多压舱底的黑科技还没有释放出来,我会在接下来针对每天发布会的内容输出一些个人的认知和思考。
Powered by 炒股杠杆操作_炒股杠杆官网_实盘股票杠杆开户 @2013-2022 RSS地图 HTML地图